How ChatGPT Solved Database Connection Storms Under Massive Request Volumes

Operating a system like ChatGPT means handling millions of concurrent requests across regions, often with unpredictable traffic spikes. At this scale, database connection management becomes a first-order reliability concern. Even a well-provisioned database can fail if connection usage is not tightly controlled.
This article explains how ChatGPT addressed database connection exhaustion, the architectural challenges involved, and the connection pooling strategy that enabled reliable, low-latency operation at scale.
The Challenge: Connection Limits in a High-Concurrency System
ChatGPT relies on multiple backend services that interact with PostgreSQL for state, metadata, and operational data. In managed environments such as Azure PostgreSQL, each database instance enforces a maximum connection limit of 5,000 connections.
At ChatGPT’s scale, several factors quickly push systems toward that ceiling:
Thousands of application instances scaling horizontally
Short-lived but highly concurrent requests
Bursty traffic patterns driven by user demand
Idle connections accumulating across services
Historically, these conditions can trigger connection storms, where a sudden spike in traffic exhausts all available database connections, leading to cascading failures and degraded user experience.
Why Traditional Pooling Was Insufficient
Application-level connection pools alone were not enough. While each service maintained its own pool, the aggregate effect across hundreds or thousands of instances resulted in:
Unbounded growth in total database connections
Large numbers of idle but reserved connections
High connection churn during traffic spikes
The database became the bottleneck—not because of query load, but because of connection management overhead.
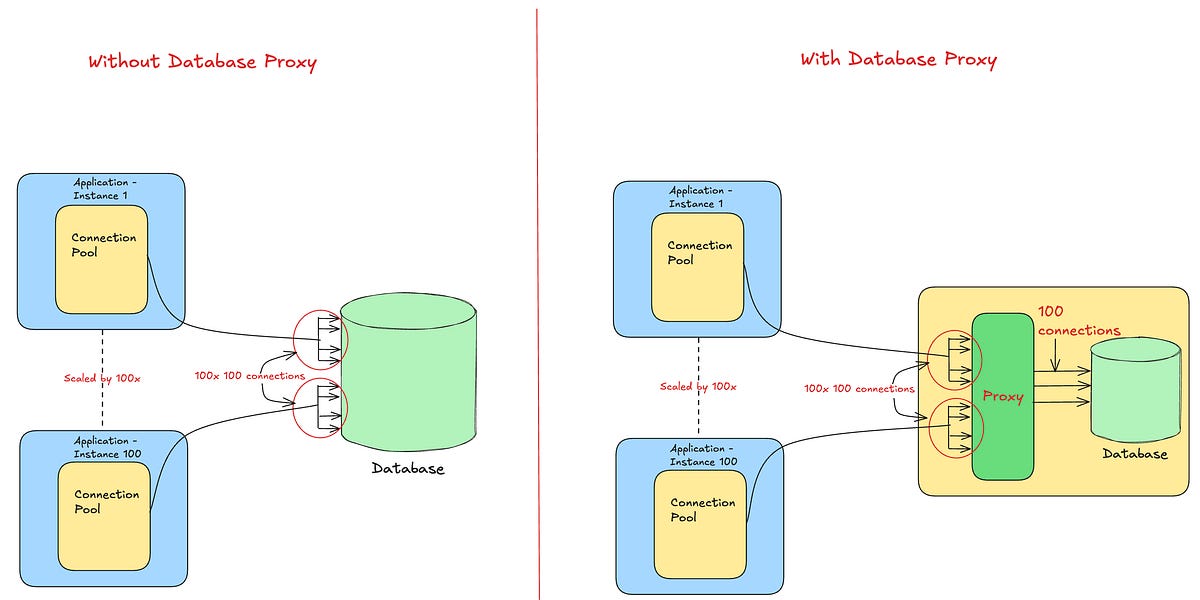
The Solution: Centralized Connection Pooling with PgBouncer
To address this, ChatGPT introduced PgBouncer as a dedicated connection pooling proxy layer between application services and PostgreSQL.
ChatGPT Services → PgBouncer → Azure PostgreSQL
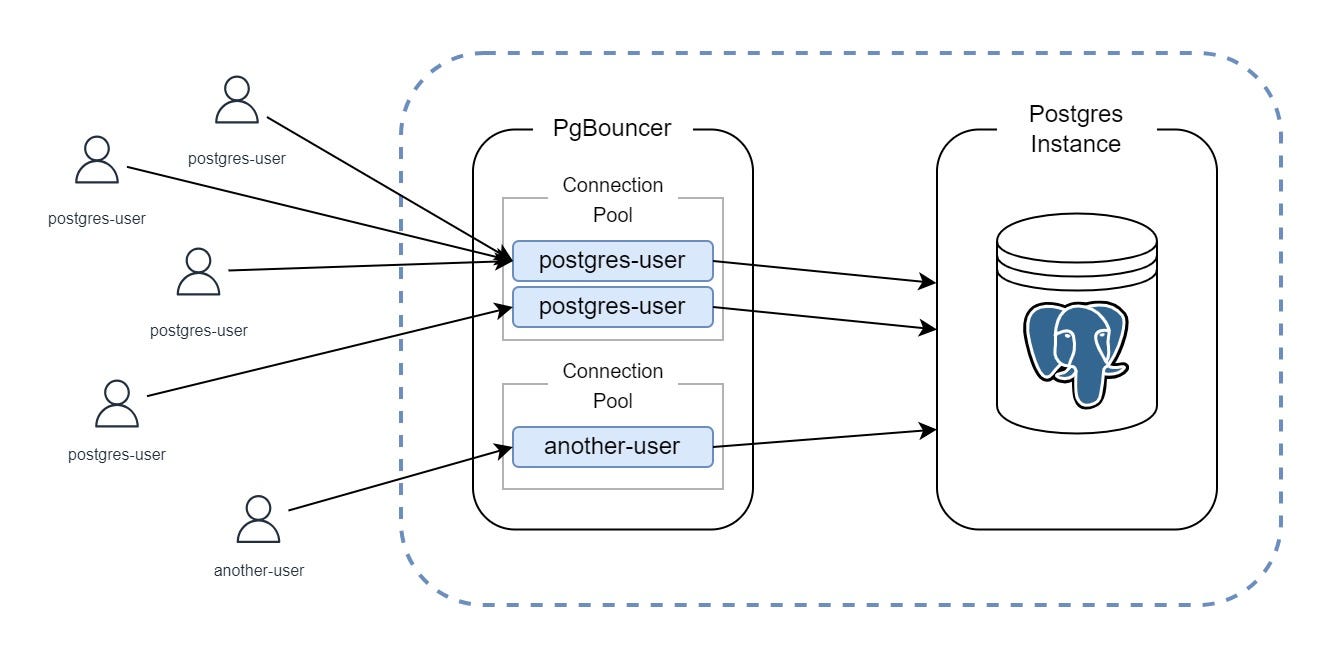
PgBouncer fundamentally changed how connections were used:
Client services no longer opened direct database connections
A controlled number of backend PostgreSQL connections were maintained
Thousands of client requests were multiplexed over a much smaller pool
Transaction and Statement Pooling at Scale
ChatGPT primarily relied on transaction pooling, with selective use of statement pooling for stateless workloads.
Transaction Pooling
Database connections are allocated only for the duration of a transaction
Connections are returned immediately after commit or rollback
Enables aggressive reuse without sacrificing correctness
Statement Pooling
Connections are borrowed per SQL statement
Maximizes throughput for simple, read-heavy operations
Used only where multi-statement transactions were unnecessary
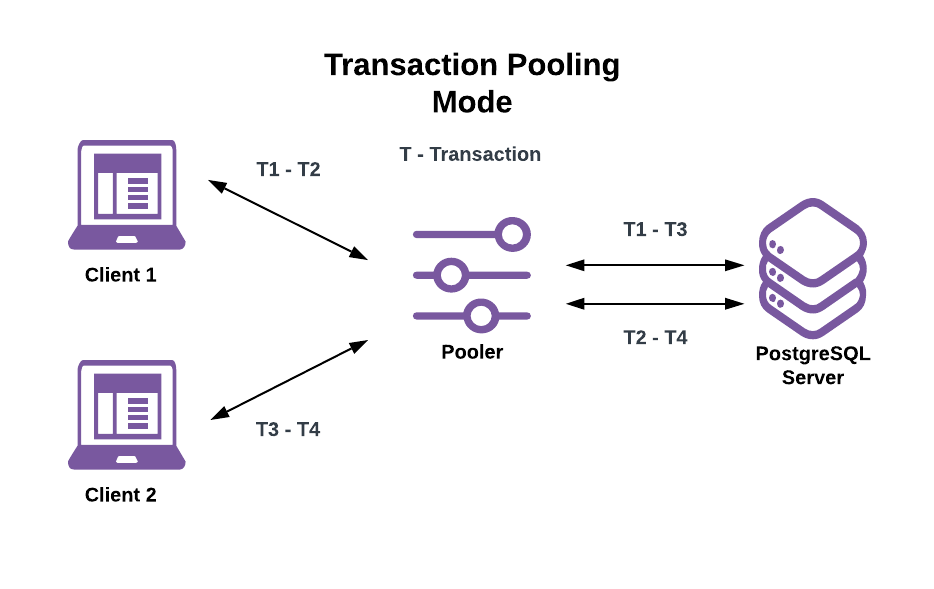
These modes dramatically reduced the number of active database connections while maintaining high throughput.
Performance Impact
The results were both measurable and significant.
Average connection time dropped from ~50 ms to ~5 ms
Active database connections decreased by an order of magnitude
Connection storms were effectively eliminated
By reusing existing connections instead of constantly opening new ones, PgBouncer removed a major source of latency and instability.
Regional Co-Location to Reduce Connection Cost
At ChatGPT’s scale, network locality matters. Inter-region database connections are expensive—not just in latency, but in how long a connection remains occupied.
To minimize this:
PgBouncer instances were co-located with client services and PostgreSQL replicas
Regional traffic was terminated locally whenever possible
Connection hold times were minimized, improving pool efficiency
Configuration as a Reliability Feature
PgBouncer’s effectiveness depends heavily on configuration. ChatGPT treated this as a reliability concern, not an afterthought.
Critical settings included:
Idle timeouts to prevent connection leaks
Strict pool size limits aligned with PostgreSQL capacity
Conservative reserve pools to absorb traffic spikes
Without these safeguards, even a pooling proxy can become a source of exhaustion.
The Outcome
By centralizing connection management through PgBouncer and using aggressive pooling modes, ChatGPT transformed database connections from a scalability risk into a controlled resource.
This approach allowed the system to:
Sustain massive concurrent request volumes
Maintain low and predictable latency
Avoid cascading failures caused by connection storms
Key Takeaway
At large scale, databases fail more often from connection mismanagement than from query load.
ChatGPT’s architecture reflects this reality—treating database connections as a scarce, shared resource and enforcing strict reuse through a dedicated pooling layer.